What is a Feature Scaling?
- Dr Dilek Celik
- Jul 18, 2025
- 5 min read
Introduction to Feature Scaling

In the world of machine learning, data is everything. But raw data isn't always perfect. Often, it contains features that span vastly different scales—think income in the thousands versus age in single or double digits. This is where feature scaling comes into play. It's a pre-processing technique that transforms features to a common scale without distorting differences in the ranges of values.
Feature scaling ensures that no single feature dominates the others just because of its numeric range. This is especially vital when dealing with algorithms that rely on distance calculations or gradient descent.
Real-World Example of Feature Scaling Impact
Imagine you're building a model to predict housing prices. Your features include number of bedrooms, square footage, and age of the home. Square footage might range from 500 to 5000, while age could vary from 1 to 100. If you don't scale these features, your model may focus heavily on square footage simply because of its larger magnitude—even if age is just as predictive.
In a real project, a team working on a rental price prediction noticed that their unscaled model skewed heavily toward area size. After implementing Min-Max scaling, accuracy improved by over 20%, validating the power of feature scaling.
Algorithms That Require Feature Scaling
Feature scaling isn't a luxury—it’s often a necessity for many models. Here's a quick look at algorithms that are highly sensitive to feature scales:
K-Nearest Neighbors (KNN): Uses Euclidean distance—scaling is crucial.
Support Vector Machines (SVM): Kernel calculations are sensitive to scale.
Logistic Regression & Linear Regression: Both rely on gradient descent.
Neural Networks: Scaled inputs allow faster and more reliable convergence.
PCA (Principal Component Analysis): Results vary wildly with unscaled data.
Tree-based models (like Random Forest or XGBoost) aren’t affected as much and usually don’t require scaling.
What Happens Without Feature Scaling?
Skipping feature scaling can be a silent killer in machine learning workflows. Here’s what could go wrong:
Misleading predictions: One feature can dominate due to its scale.
Slower training: Especially for models using gradient descent.
Poor generalization: The model may perform well on training data but fail on real-world data.
Even in cases where performance isn’t drastically reduced, lack of feature scaling can make training unpredictable and unstable.
Benefits of Feature Scaling
Feature scaling isn’t just a preprocessing step—it’s an efficiency booster. Here's why:
Uniform feature contribution: Each variable plays an equal part in model learning.
Faster convergence: Scaled features reduce the optimization time during training.
Better accuracy: Algorithms produce more reliable and interpretable results.
Improved metrics: You’ll likely see better precision, recall, and F1 scores.
Overview of Feature Scaling Techniques
Let’s dive into the most popular techniques for scaling features:
Technique | Description | Best For |
Min-Max Scaling | Rescales features to a specific range (usually [0,1]) | When data is uniformly distributed |
Standardization | Centers data around 0 with a standard deviation of 1 | Data with normal distribution |
MaxAbs Scaling | Scales based on maximum absolute value | Sparse data or zero-centered data |
Robust Scaling | Uses median and IQR, robust to outliers | Datasets with extreme values |
Let’s explore each one in more detail.
Min-Max Scaling Explained
Min-Max Scaling transforms data into a defined range, often between 0 and 1. The formula:

Advantages:
Simple to implement
Preserves relationships
Disadvantages:
Sensitive to outliers
Use when: You’re dealing with algorithms like KNN or neural networks and your data doesn’t have significant outliers.
Standardization (Z-score Normalization)
This method rescales the data so it has a mean of 0 and a standard deviation of 1. The formula:

Advantages:
Works well with most algorithms
Handles skewed data better than Min-Max
Use when: You need a stable method for SVMs or logistic regression.
MaxAbs Scaling: Centered Range with Efficiency
MaxAbs scaling is a lesser-known but effective technique that scales each feature by its maximum absolute value.
Best for:
Data that’s already zero-centered
Sparse matrices
It’s particularly useful in natural language processing or recommendation systems where the data is mostly zeros.
Robust Scaling for Outlier-Heavy Data
Robust Scaling uses the median and interquartile range (IQR) instead of mean and standard deviation, making it resistant to outliers.
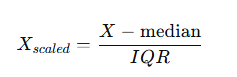
Use when:
Your dataset has extreme values that shouldn’t skew the scaling
You want a balance between Min-Max and Z-score scaling
Visual Comparison of Feature Scaling Techniques
Here’s how the same feature looks after applying different scaling methods:
Method | Visualization |
Original Data |  |
Min-Max Scaling |  |
Standardization |  |
Robust Scaling |  |
When You Should Scale Your Features
Scale your data when:
Your model depends on distance or gradient descent.
You observe one feature overpowering others.
You're preparing inputs for deep learning models.
When Feature Scaling Is Not Required
There’s no need to scale features for:
Tree-based models like Decision Trees, Random Forest, and XGBoost.
Naïve Bayes, which uses probabilities and not distances.
Rule-based models or interpretable logic systems.
Best Practices for Applying Feature Scaling
Use pipelines: Automate the process using Pipeline in Scikit-learn.
Scale only after splitting: Prevent data leakage by scaling only on training data.
Check distribution: Pick a scaling method based on feature distributions.
Tools & Libraries for Feature Scaling
Scikit-learn: StandardScaler, MinMaxScaler, RobustScaler, and more.
Pandas: Easy data inspection and normalization.
TensorFlow/Keras: Normalization() layers for deep learning.
Common Pitfalls and How to Avoid Them
Data leakage: Always fit scalers only on training data.
Incorrect application: Don’t apply different scalers to train/test sets.
Over-standardization: Use the right scaler for the right data distribution.
Feature Scaling in Big Data Environments
When handling massive datasets:
Use batch normalization in deep learning frameworks.
Opt for incremental scalers like PartialFit in Scikit-learn.
Leverage Apache Spark’s MLlib for distributed scaling.
FAQs About Feature Scaling
Q1: Is feature scaling mandatory for all models?
No. Models like decision trees, random forests, and XGBoost don’t require it.
Q2: What’s the best scaler for outlier-heavy data?
RobustScaler is ideal since it’s not affected by outliers.
Q3: Should I scale categorical variables?
No, you should encode them (e.g., one-hot or label encoding), not scale.
Q4: Can I use scaling with pipelines?
Absolutely! Use Scikit-learn pipelines for efficient and safe scaling.
Q5: When should I apply feature scaling during preprocessing?
Always after data splitting and before model training.
Q6: What’s the difference between normalization and standardization?Normalization rescales to a range (like 0–1); standardization centers data with zero mean and unit variance.
Conclusion: Embrace Feature Scaling for Smarter Models
In summary, feature scaling isn't just a technical formality—it's a key to unlocking faster, more accurate, and more stable machine learning models. Whether you're using a basic logistic regression or a complex neural network, incorporating scaling ensures that your data works for you, not against you. With so many scaling techniques available, you can always find the one that fits your dataset and model type perfectly.



Perfect explanation.