Using Machine Learning Models to Create Multi-Level Fraud Detection Systems
- Dr Dilek Celik
- Jul 28, 2025
- 5 min read
Updated: Jul 31, 2025

1 Introduction to Multi-Level Fraud Detection
In today’s hyperconnected digital economy, fraud is one of the biggest threats to businesses, financial institutions, and consumers. From phishing and account takeovers to synthetic identities and money laundering, fraudsters use increasingly sophisticated techniques to exploit vulnerabilities in financial systems. To counter this, companies need more than traditional rule-based fraud detection—they need multi-level fraud detection systems powered by machine learning (ML).
Multi-level fraud detection combines several layers of defense, including onboarding analysis, KYC verification, device identity tracking, behavioral analytics, and transactional monitoring. Each layer leverages different ML models and static rules to detect fraudulent patterns at various stages of the customer lifecycle.
This approach creates a dynamic, adaptive, and highly effective fraud prevention framework. In this article, we’ll explore in detail how machine learning models are implemented at each stage, how to design such systems, and the challenges and future directions of multi-layered fraud detection.
2 Why Fraud Detection Needs a Multi-Layered Approach
The Evolving Nature of Fraud
Fraud is no longer limited to simple credit card misuse. Criminals now use synthetic identities, social engineering, and bot-driven attacks to bypass traditional defenses. A single-layer detection system may catch one type of fraud but fail against others.
Multi-Level Detection as a Solution
A multi-layered approach ensures that fraud detection happens at multiple stages:
At onboarding: Detecting fake accounts and synthetic identities.
During account login: Monitoring device fingerprints and session anomalies.
During transactions: Assessing the risk based on sender/recipient profiles and transaction behavior.
This layered structure makes it exponentially harder for fraudsters to bypass the system.

3 Role of Machine Learning Models in Fraud Detection
Why Machine Learning?
Traditional fraud detection relied on static rules (e.g., flagging all transactions above $10,000). While effective for known patterns, these rules struggle with new or evolving threats. Machine Learning Models for Fraud Detection overcome this by learning patterns from historical data and detecting anomalies that humans or rules can’t spot.
Supervised vs Unsupervised Learning for Fraud Detection
Fraud detection uses two primary ML approaches:
Supervised Learning:
Works with labeled datasets (fraud vs non-fraud).
Examples: Logistic Regression, Random Forest, Gradient Boosting.
Ideal for detecting known fraud types.
Unsupervised Learning:
Works with unlabeled datasets to detect anomalies.
Examples: Autoencoders, Isolation Forest, Clustering (K-Means).
Useful for identifying new fraud patterns.
Many systems use a hybrid approach—combining supervised and unsupervised models for maximum coverage.
4 Key Features for Fraud Detection Models
The performance of any Machine Learning Models for Fraud Detection depends heavily on features extracted from data.
Common features include:
User behavior: Login times, clickstream data, frequency of access.
Device data: IP address, geolocation, device fingerprinting.
Transaction details: Amount, frequency, unusual transaction patterns.
Sender & recipient profiles: Historical behavior, social network analysis.

Feature Engineering for Better Fraud Detection
Good fraud detection systems rely on advanced feature engineering:
Derived features (e.g., transaction velocity, time between logins).
Aggregated metrics (e.g., average transaction amount over the last 30 days).
Behavioral biometrics (e.g., typing speed, mouse movements).
5 Stages of Multi-Level Fraud Detection Systems
The diagram provides a high-level view of a multi-level fraud detection system. Let’s break it down.

Step 1: Sign-Up & Onboarding Analysis
When a user signs up, onboarding models detect fake or synthetic accounts using:
Document verification models (e.g., OCR + CNN for ID verification).
Behavioral analysis: Detecting bot-like sign-up patterns.
Email & phone risk scoring: Using external databases (e.g., HaveIBeenPwned).
Step 2: KYC Verification Models
KYC (Know Your Customer) is critical for preventing identity fraud.
Face matching with IDs using CNN-based face recognition models.
Document forgery detection using ML-based image anomaly detection.
Risk-based KYC: Assigning dynamic KYC levels based on user risk.
Step 3: Device Identity & Session Analysis
At login, ML models track device identity and session behavior:
Device fingerprinting using unsupervised clustering to identify new devices.
Session anomaly detection using sequence models (e.g., LSTM networks) to spot unusual login behaviors.
Step 4: Account Activity & Open Balance Monitoring
Accounts with sudden unusual activity are flagged.
Behavioral profiling: Comparing current actions to historical behavior.
Velocity checks: Identifying rapid, high-volume account operations.
Step 5: Transactional Analysis & Risk Scoring
Before approving a transaction, ML models analyze:
Sender/recipient profiles using supervised classification models.
Network analysis (e.g., Graph Neural Networks) to detect fraud rings.
Risk scoring combining multiple ML outputs into a final fraud probability.
6 Typical Approach to Transactional Analysis
The below shared diagram shows standard transactional analysis pipeline.
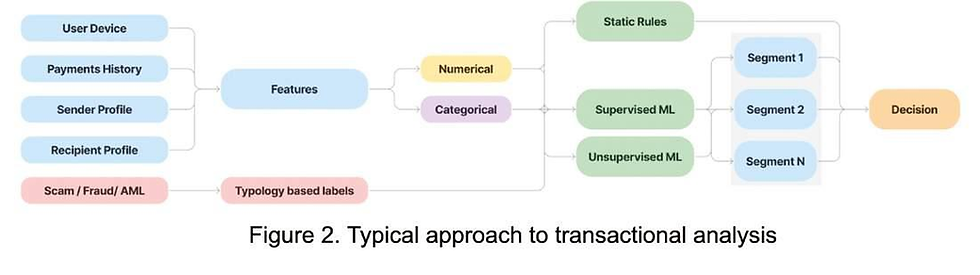
Features: Device, Payment History, and Profiles
Device-based features: Location, browser type, and device reputation.
Payment history: Previous transaction amounts, times, and patterns.
Sender & recipient profiling: Social graph analysis to detect suspicious relationships.
Typology-Based Labels for Fraud Detection
Transactions are labeled as Scam, Fraud, or AML-related using typology-based labels, enabling supervised learning models to classify similar cases effectively.
Static Rules vs Machine Learning Models
Static Rules: Quick filters for known high-risk activities.
Supervised ML: Classifies transactions using historical fraud data.
Unsupervised ML: Detects previously unseen fraud behaviors.
7 Building Effective Multi-Level Fraud Detection Models
Data Preprocessing & Feature Engineering
Data cleaning: Handling missing values, outliers, and normalization.
Feature transformation: Converting categorical features into embeddings.
Data enrichment: Incorporating third-party data (IP intelligence, blacklists).
Combining Static Rules with ML Models
A hybrid system uses rules for real-time blocking and ML models for deeper analysis:
Example: Block transactions >$50,000 instantly (rule) while running ML scoring for smaller but suspicious ones.
Real-Time vs Batch Processing in Fraud Detection
Real-time systems: Analyze transactions instantly to block fraud before completion.
Batch systems: Perform deeper analysis overnight to identify emerging fraud trends.
8 Advantages of Multi-Level ML-Based Fraud Systems
Adaptive defense: Learns new fraud tactics dynamically.
Reduced false positives: Smarter models minimize unnecessary alerts.
Improved compliance: Meets AML and KYC regulatory requirements.
Scalable: Handles millions of transactions in real time.
9 Challenges in Building Multi-Layer Fraud Detection Models
Data quality issues: Imbalanced datasets with few fraud cases.
Model interpretability: Explaining ML decisions to regulators.
Constant evolution of fraud: Models require frequent retraining.
10 Future Trends in AI-Driven Fraud Detection
Graph-based ML: Identifying fraud networks using graph algorithms.
Federated Learning: Collaborative fraud detection without sharing raw data.
Explainable AI (XAI): Making ML models more transparent for compliance.
11 Case Study: Multi-Level Fraud Protection in FinTech
A leading FinTech platform implemented a five-layer fraud detection system:
Onboarding: ML-based synthetic identity detection.
KYC: AI-driven ID forgery detection.
Device monitoring: Session anomaly detection.
Transaction scoring: Supervised + Unsupervised models.
Outcome: Fraud losses dropped by 45% in 6 months while improving user experience.

12 FAQs
1. What is multi-level fraud detection?
A layered approach using different models and checks across onboarding, login, and transactions.
2. Why is ML important for fraud detection?
It detects patterns and anomalies beyond rule-based systems.
3. What models are best for fraud detection?
Random Forest, Gradient Boosting, Neural Networks, Autoencoders, and Graph ML models.
4. How does transactional analysis work?
It evaluates transaction features, sender/recipient profiles, and applies supervised/unsupervised ML models.
5. Can multi-level systems reduce false positives?
Yes, they combine contextual rules with ML to reduce unnecessary alerts.
6. What industries use these systems?
Banking, e-commerce, crypto, insurance, and payment platforms.
13 Conclusion
Multi-level fraud detection systems powered by machine learning are no longer optional—they’re essential for modern fraud prevention. By integrating supervised and unsupervised ML models across multiple checkpoints (onboarding, KYC, device tracking, and transactions), organizations can proactively combat evolving fraud tactics.
The future of fraud detection lies in AI-driven, explainable, and collaborative systems that adapt in real time and provide both security and seamless customer experiences.



Comments